
Orchestrated Multi-Agent + Multi-LLM Architecture
🚀 My First Post as an AI Architect — Multi-Agent + Multi-LLM Systems (Free Stack)

I’ve been exploring a powerful pattern for building scalable AI systems:
👉 Orchestrated Multi-Agent + Multi-LLM Architecture
The key shift:
❌ Don’t rely on one LLM
✅ Use the right model for the right task
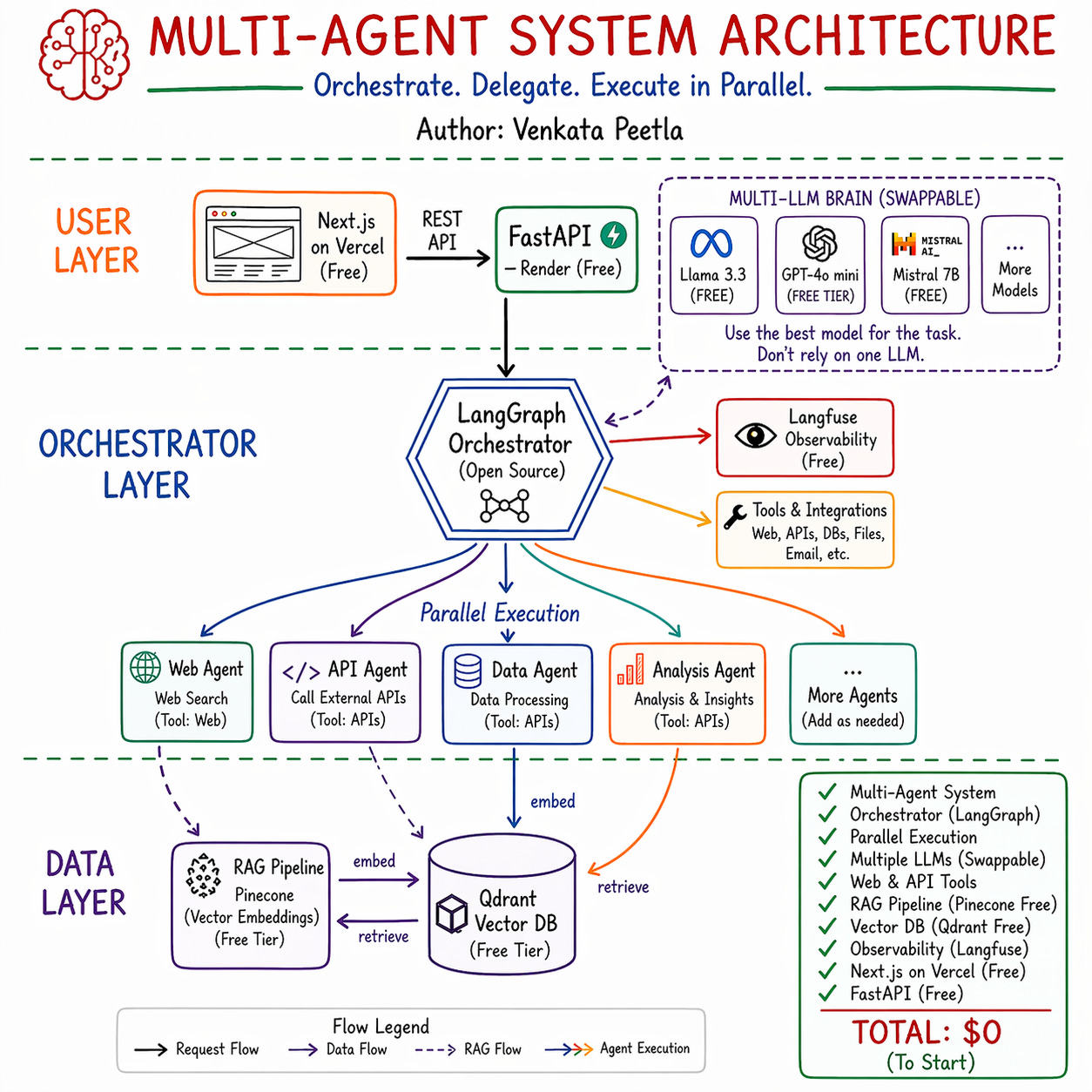
🧠 Architecture Overview
At the core is an Orchestrator (LangGraph) that:
Breaks down complex tasks
Delegates to specialized agents
Executes them in parallel
Routes to the best LLM dynamically
🤖 Multi-LLM Brain (Swappable)
Instead of a single model, this system can leverage:
Llama 3.3 (free)
GPT-4o mini (free tier)
Mistral 7B (free)
more models as needed
💡 Each model is used based on task complexity, cost, and latency
⚙️ Agent Layer (Specialized + Parallel)
🌐 Web Agent → real-time search
🔗 API Agent → external integrations
📊 Data Agent → processing & transformations
📈 Analysis Agent → insights & reasoning
➕ Add more agents as needed
🔍 Data + RAG Layer
RAG Pipeline: Pinecone (free tier)
Vector DB: Qdrant (free tier)
Enables:
Context-aware responses
Long-term memory
Knowledge grounding
👀 Observability
Langfuse for tracing, debugging, and improving agent workflows
🌐 User Layer
Frontend: Next.js
Deployment: Vercel (Free)
Backend: FastAPI
🔥 Why This Pattern Matters
Traditional LLM apps hit limits:
One model ≠ best for all tasks
Limited scalability
Hard to debug
This architecture enables:
✔ Model flexibility (multi-LLM)
✔ Task specialization (multi-agent)
✔ Parallel execution (speed 🚀)
✔ Observability (production-ready)
💡 Key Takeaway
You can build a production-grade AI system today with:
Multi-agent orchestration
Multi-LLM routing
RAG + memory
Observability
👉 All starting at $0 (free tiers)
This is just the beginning.
Next, I’ll share:
Real-world enterprise use cases
Design patterns for scaling
Implementation deep-dives
💬 Curious — are you building with:
Single LLM apps or multi-agent + multi-LLM systems?